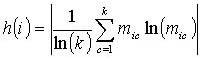
Fuzzy classification produces a new multivariate data set with the same spatial support as the original data set. In this new data set, the locations are associated with new variables, fuzzy membership values for each of the classes. BoundarySeer can find boundaries for this new data set in many ways.
Boundary Membership Values (BMVs) can be derived from (1) wombling on the fuzzy classes, (2) wombling with location uncertainty on the classes, (3) spatially constrained clustering, (4) the confusion index, or (5) the classification entropy index.
You may find boundaries using wombling, confusion index, and classification entropy directly from the fuzzy classification dialog. For location uncertainty and spatially constrained clustering, first create fuzzy classes, then perform the boundary detection procedure.
The confusion index is simply the ratio of the second highest class membership value to the highest. If the two values are similar, the confusion index returns a value close to one, indicating high confusion about class membership. If the two values are very different, then the confusion index is closer to zero, indicating less confusion about class membership.
BoundarySeer uses the confusion index as a Boundary Likelihood Value (BLV). BoundarySeer calculates the confusion index for each spatial location, then all the confusion indices for the data set are used to create BMVs. The confusion index values are scaled to between 0-1, with the lowest confusion index set to 0 and the highest to 1.0. Locations with high confusion index are most transitional between classes and therefore, most boundary-like.
Classification entropy at location i, h(i), is (from Brown 1998):
where k is the number of classes, and mic is the fuzzy membership value for location i in class c. Entropy results parallel those of the confusion index, with entropy values close to one when membership is spread among the classes, and closer to zero when membership is primarily in one class.
BoundarySeer uses entropy as a BLV. BoundarySeer calculates the entropy for each spatial location, then it scales all entropy values for the entire data set to make BMVs. Entropy values are scaled to between 0-1, with the lowest value set to 0 and the highest to 1.0. Locations with high classification entropy are most transitional between classes and therefore, most boundary-like.
See also: