The fuzzy classification process
Fuzzy classification can reduce the dimensionality of multivariate data sets, by assigning the objects in the data set to k fuzzy classes. You, the user, choose the number of classes, k (see choosing k).
BoundarySeer uses a k-means technique to create fuzzy classes. First, it assigns the locations randomly to classes. It then refines the class membership, reducing the variation within a class and maximizing the between-class variation. This process results in a new data set where the original spatial locations are described only by membership in the k classes.
Steps
-
Initialization.
-
An initial partition of k clusters is established. Cluster membership is initially random.
-
Select a value for the fuzziness exponent f, phi (values can be between 1 and 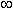 , 2 is a good initial value).
, 2 is a good initial value).
-
Select a value for the stopping criterion e, epsilon. It determines the level of convergence necessary before quitting (McBratney and de Gruijter 1992 recommend e = 0.001).
-
Refinement. BoundarySeer compares dissimilarity between classes using Euclidean distance. BoundarySeer rearranges class memberships iteratively to minimize the within-class least squared-error function, J.
-
Finalization.
-
The procedure terminates when the largest proportional difference between the matrices is ‹ e, the stopping criteria.
-
Once the final partition has been selected, it is saved as a new data set with the same X-Y values as the original data set, and variable(s) denoting class membership. Unless renamed by the user, the data set has a "Classes" suffix.
Please note: the location of samples is not taken into account in the classification process. Each sample location is assigned classification values regardless of the values of adjacent locations.
See also: