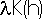 , where
, where 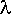 is the intensity, or mean number
of cases per unit area.
is the intensity, or mean number
of cases per unit area. |
Ho |
The distribution of disease cases is a spatial Poisson point process, where L(h) = h. |
|
Ha |
The distribution of disease cases is clustered, at some scales L(h)>h. |
Ripley's K-function compares the pattern of the data to that produced
by a homogeneous Poisson point process, where cases are considered "events."
The
expected number of other cases within a fixed distance (h) of one case
is , where is the intensity, or mean number
of cases per unit area.
K(h) can be estimated by the following formula (from Bailey and Gatrell 1995)
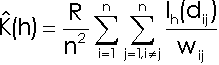
Where R is the area of the region of interest, n is the total number of cases in region R, dij is the distance between the ith and jth cases , and Ih(dij) is the indicator function which is 1 if dij < h and 0 otherwise. Essentially, it sums the cases within distance h of each location in the dataset (each i). wij is an edge correction factor, the conditional probability that a case is observed in the region, given that it is dij from the event i.
![]()